Regularization Matters in (Reinforcement) Learning
Yuan Zhang, Neurorobotics Lab, University of Freiburg
Reinforcement learning (RL) is recognized as lacking generalization and robustness under environmental perturbations, which excessively restricts its application for real-world robotics. To handle such problems, regularization is definitely a class of methods we could look into, as we don‘t want our learning to be overfitting. Here are some selective works in this direction.
Robust Reinforcement Learning in Continuous Control Tasks with Uncertainty Set Regularization
Zhang, Yuan, Jianhong Wang, and Joschka Boedecker. 2023. “Robust Reinforcement Learning in Continuous Control Tasks with Uncertainty Set Regularization.” In . https://openreview.net/forum?id=keAPCON4jHC.
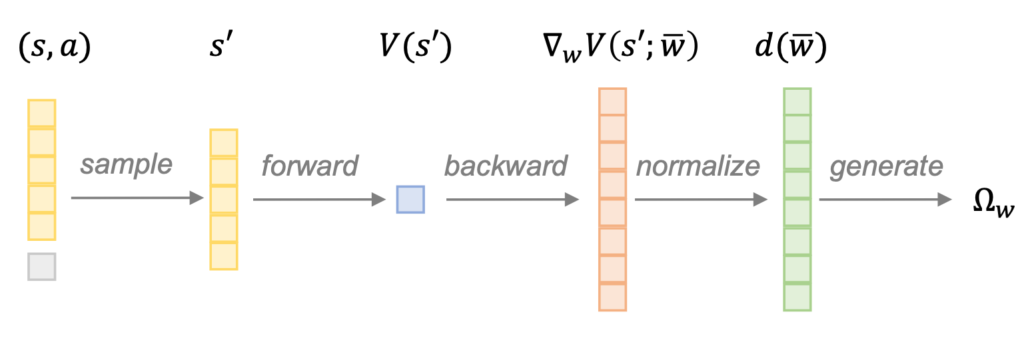
Reinforcement learning (RL) is recognized as lacking generalization and robustness under environmental perturbations, which excessively restricts its application for real-world robotics. Prior work claimed that adding regularization to the value function is equivalent to learning a robust policy under uncertain transitions. Although the regularization-robustness transformation is appealing for its simplicity and efficiency, it is still lacking in continuous control tasks. In this paper, we propose a new regularizer named Uncertainty Set Regularizer (USR), to formulate the uncertainty set on the parametric space of a transition function. To deal with unknown uncertainty sets, we further propose a novel adversarial approach to generate them based on the value function. We evaluate USR on the Real-world Reinforcement Learning (RWRL) benchmark and the Unitree A1 Robot, demonstrating improvements in the robust performance of perturbed testing environments and sim-to-real scenarios.

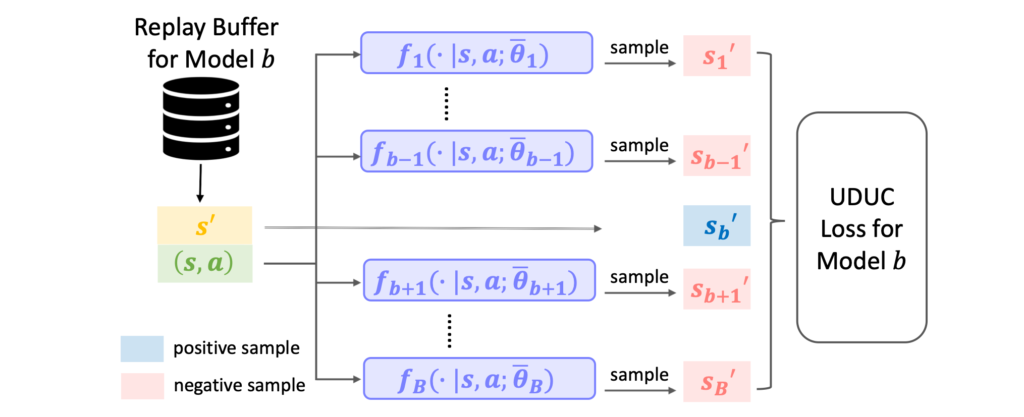
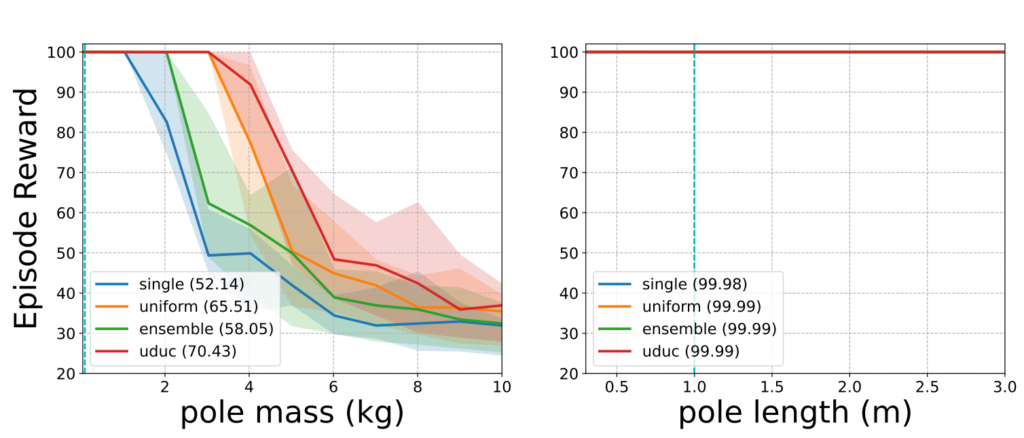
UDUC: An Uncertainty-driven Approach for Robust Control
Zhang, Yuan,Jasper Hoffman, and Joschka Boedecker. 2024. “UDUC: An Uncertainty-driven Approach for Robust Control.” https://arxiv.org/abs/2405.02598.
Learning-based techniques have become popular in both model predictive control (MPC) and reinforcement learning (RL). Probabilistic ensemble (PE) models offer a promising approach for modelling system dynamics, showcasing the ability to capture uncertainty and scalability in high-dimensional control scenarios. However, PE models are susceptible to mode collapse, resulting in non-robust control when faced with environments slightly different from the training set. In this paper, we introduce the uncertainty-driven robust control (UDUC) loss as an alternative objective for training PE models, drawing inspiration from contrastive learning. We analyze the robustness of UDUC loss through the lens of robust optimization and evaluate its performance on the challenging Real-world Reinforcement Learning (RWRL) benchmark, which involves significant environmental mismatches between the training and testing environments.